繼續玩 Stable Duiffsion XL。
https://huggingface.co/docs/diffusers/en/using-diffusers/sdxl
一樣先裝一裝需要的東西。
pip install diffusers
from diffusers import AutoPipelineForText2Image
import torch
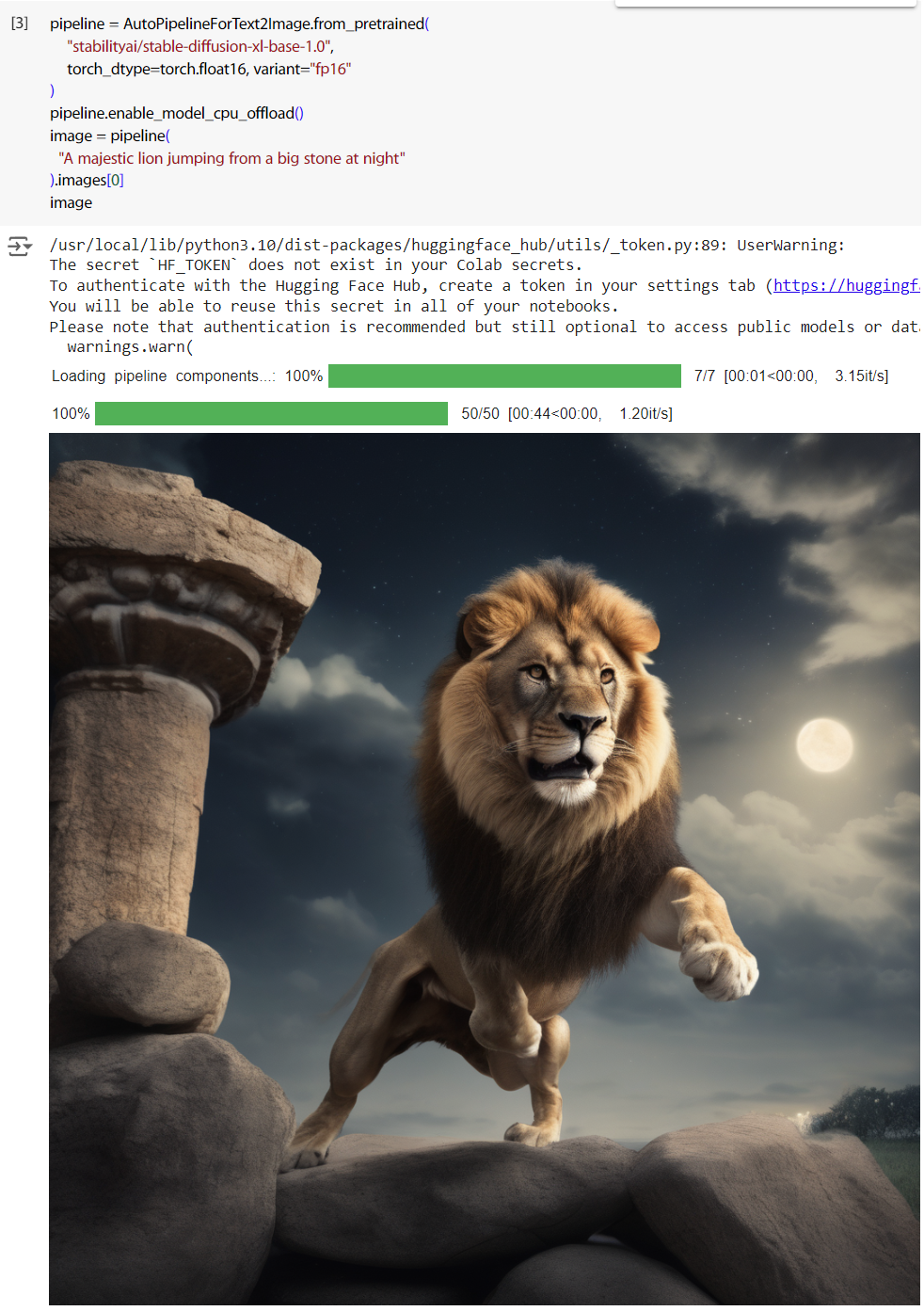
先產一張圖。
pipeline = AutoPipelineForText2Image.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16, variant="fp16"
)
pipeline.enable_model_cpu_offload()
image = pipeline(
"A majestic lion jumping from a big stone at night"
).images[0]
image
接下來我們試試看模型說的 refiner 方式,就是 Stable Diffusion XL 的特色,可以增加圖像精細度的架構。
分別把 base、refiner 讀進來。
from diffusers import DiffusionPipeline
base = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True
).to("cuda")
refiner = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=base.text_encoder_2,
vae=base.vae,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
).to("cuda")
跟剛剛同樣的 prompt,看看產出的效果。
prompt = "A majestic lion jumping from a big stone at night"
image = base(
prompt=prompt,
num_inference_steps=40,
denoising_end=0.8,
output_type="latent",
).images
image = refiner(
prompt=prompt,
num_inference_steps=40,
denoising_start=0.8,
image=image,
).images[0]
image
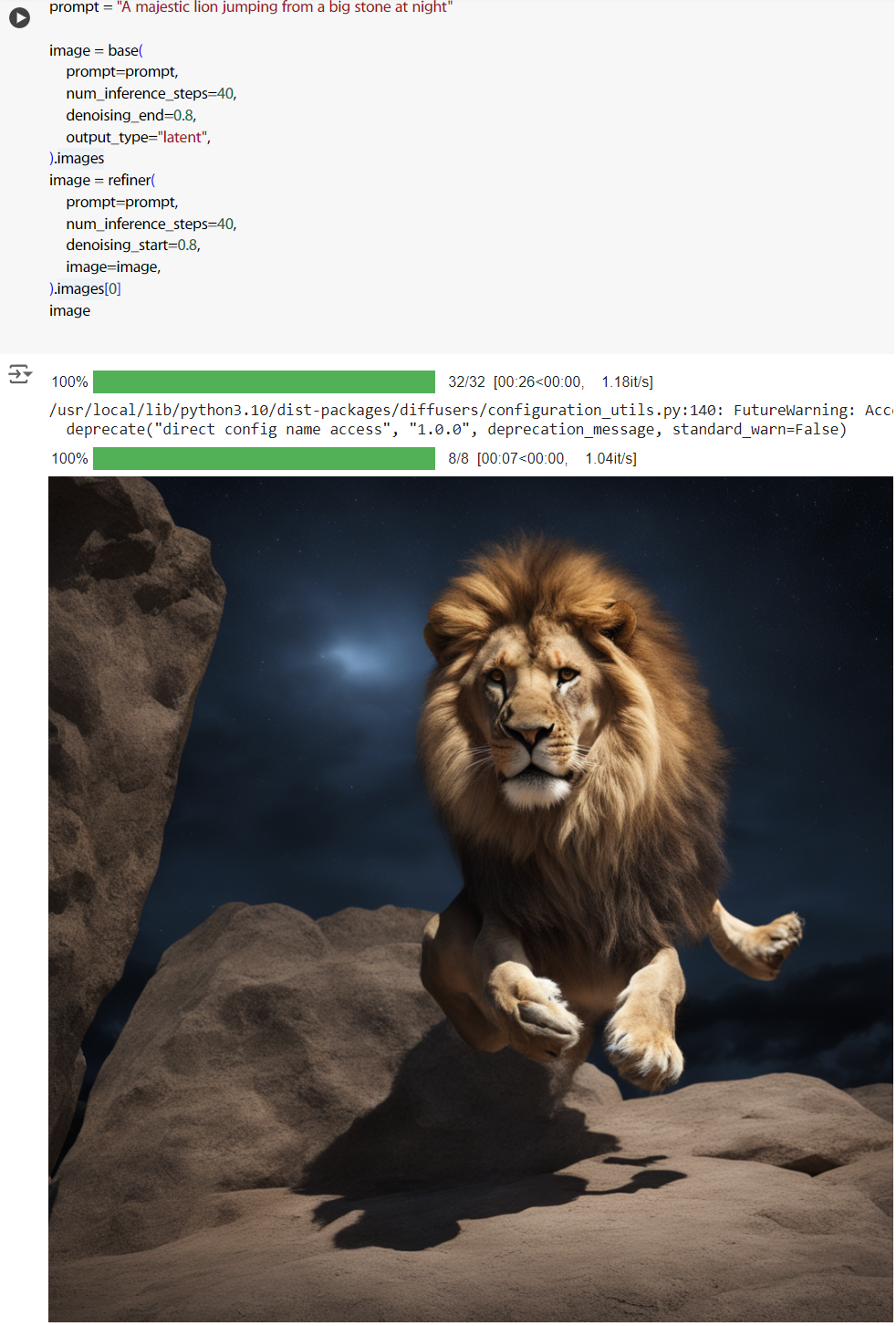
這次多給了幾個參數,num_inference_steps、denoising_end、denoising_star。num_inference_steps 是去除雜訊的步數,一般調越高影像品質越好,但同時運算速度越慢。
denoising_end=0.8 是在 base 階段的 step 的前 80% 執行 denoising,denoising_star=0.8 是在 refiner 階段的 step 的後 20% 執行 denoising。
不過我還沒看到跳過幾個 step 不去 denoising 的原因,之後確定了再來補上。
output_type 給的是 latent 而不是 PIL,沒有還原成圖片。
這個流程實際上就是先生成圖,然後將圖丟給 refiner 去加細節,所以其實也可以這樣。
from diffusers import AutoPipelineForImage2Image
base = AutoPipelineForText2Image.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
variant="fp16"
).to("cuda")
refiner = AutoPipelineForImage2Image.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True
).to("cuda")
然後生圖。
prompt = "A majestic lion jumping from a big stone at night"
image_base = base(prompt=prompt, output_type="latent").images[0]
image = refiner(prompt=prompt, image=image_base[None, :]).images[0]
image
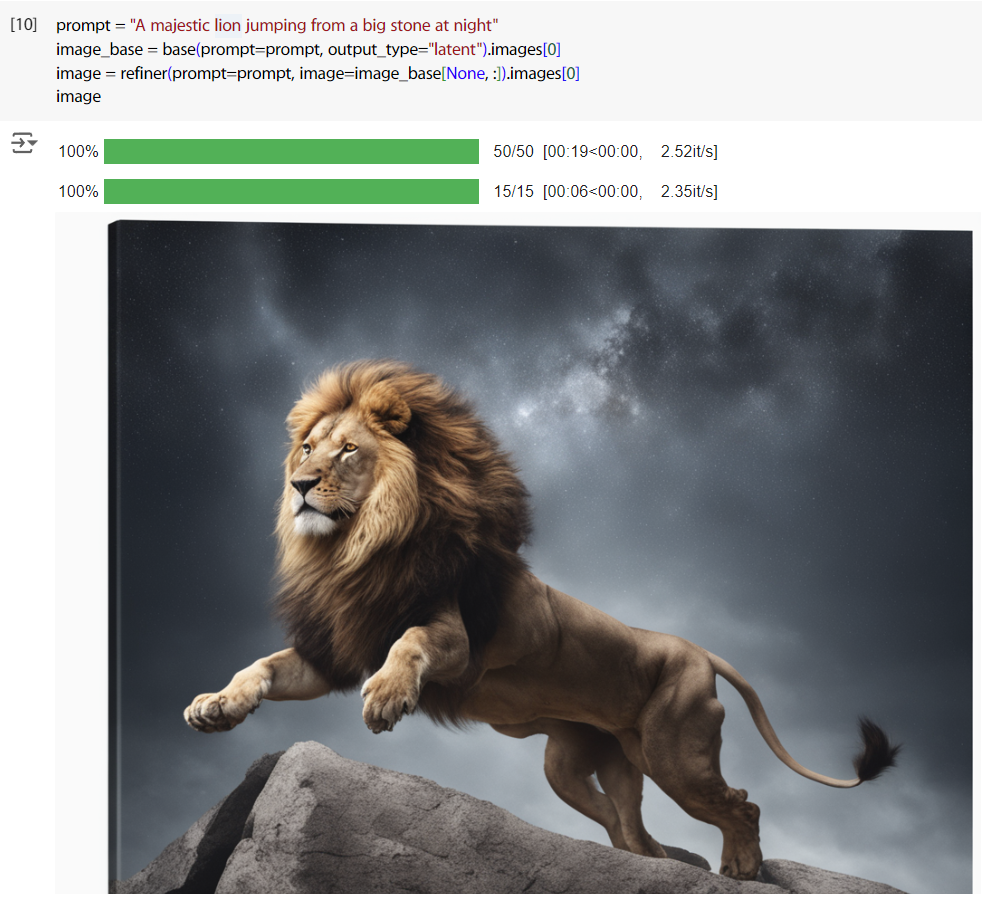
不過我也很疑惑,這邊 output_type 設為 latent 的原因應該只是想要減少一次 decode的過程吧,還是說要再將 image 壓到 latent 會讓效果變差呢?
所以試了一下。
from diffusers.utils import make_image_grid
prompt = "A majestic lion jumping from a big stone at night"
image_base = base(prompt=prompt).images[0]
image = refiner(prompt=prompt, image=image_base).images[0]
make_image_grid([image_base, image], rows=1, cols=2)
好吧,可能會。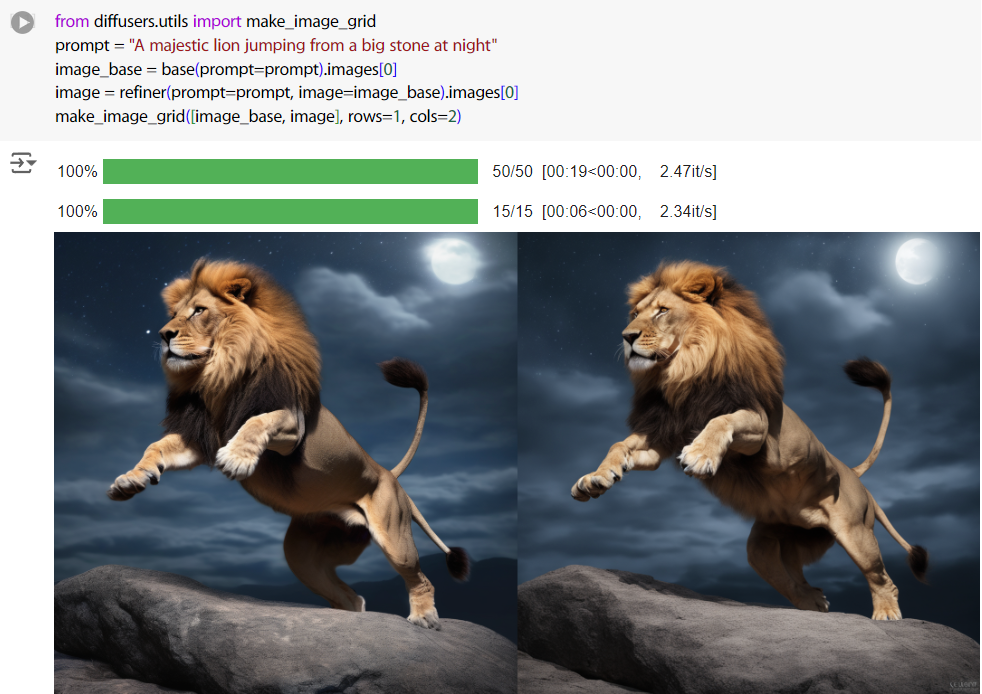
最後是,這個方法也可以直接去做 Inpaint,讀取模型的方式又變了,之後再討論,總之先照著官方來。
from diffusers import StableDiffusionXLInpaintPipeline
from diffusers.utils import load_image
base = StableDiffusionXLInpaintPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
refiner = StableDiffusionXLInpaintPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=base.text_encoder_2,
vae=base.vae,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
).to("cuda")
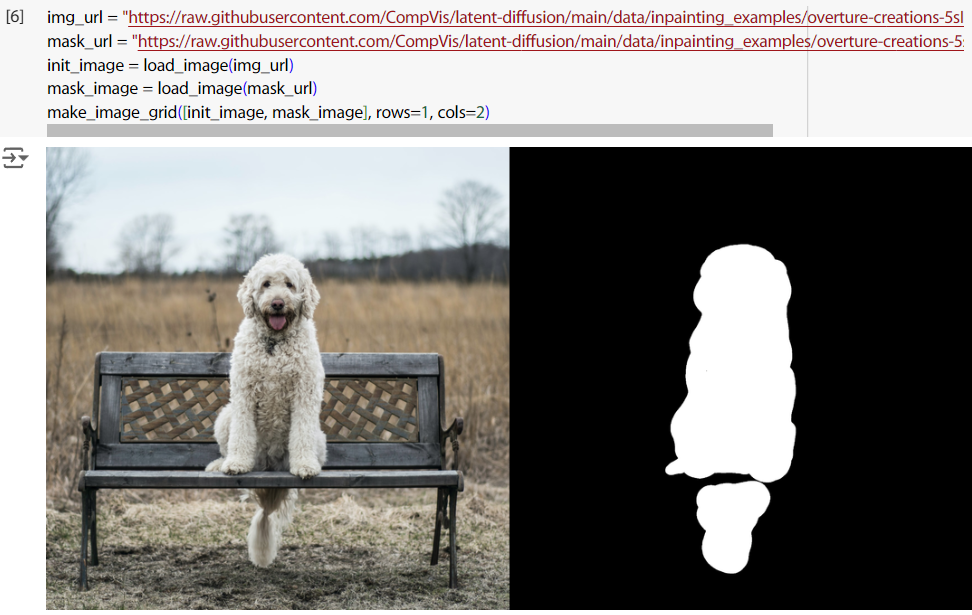
把圖讀進來。
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
init_image = load_image(img_url)
mask_image = load_image(mask_url)
make_image_grid([init_image, mask_image], rows=1, cols=2)
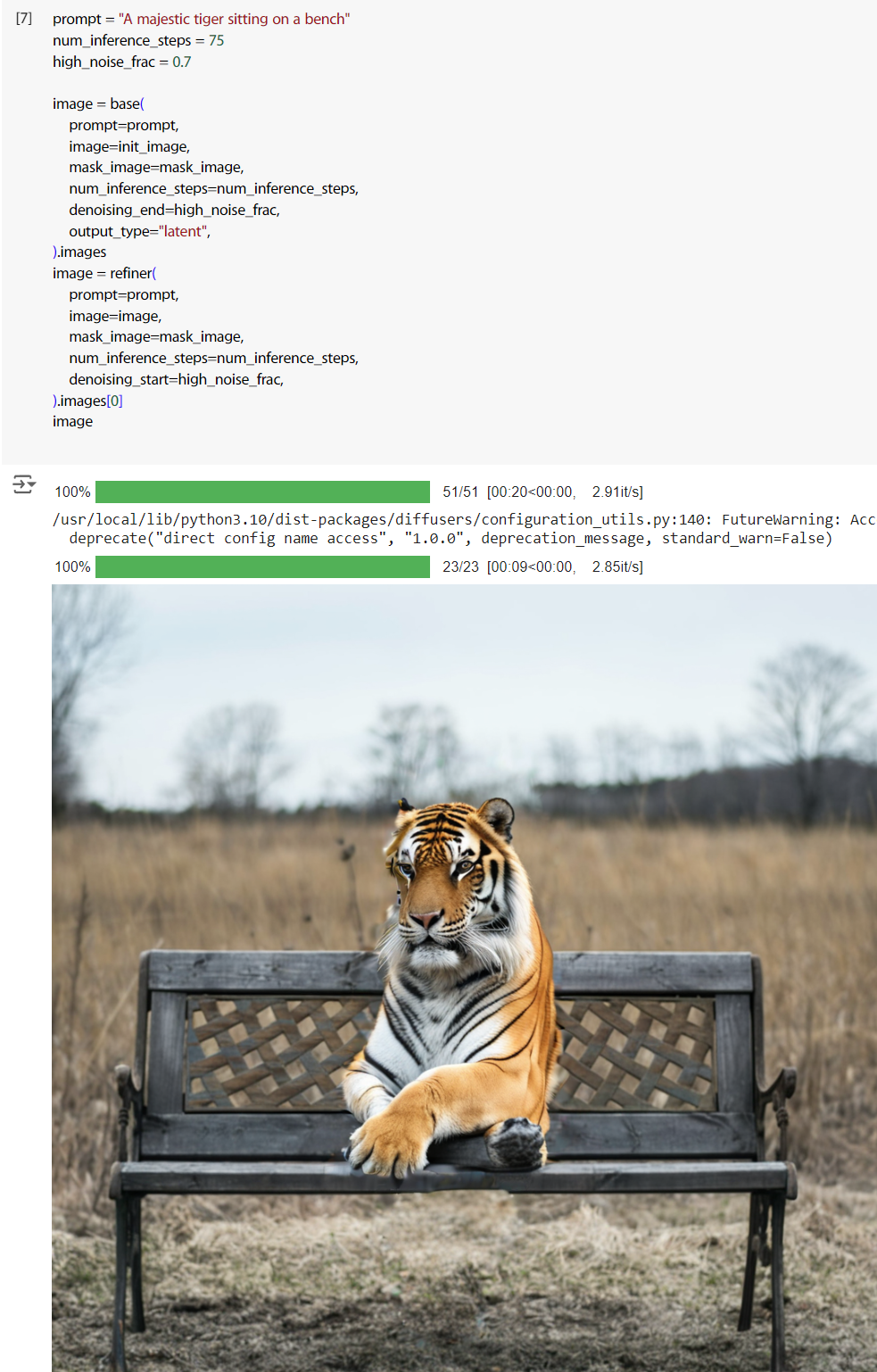
最後下 prompt 產圖。成品有點一言難盡,但至少是完成任務了。
prompt = "A majestic tiger sitting on a bench"
num_inference_steps = 75
high_noise_frac = 0.7
image = base(
prompt=prompt,
image=init_image,
mask_image=mask_image,
num_inference_steps=num_inference_steps,
denoising_end=high_noise_frac,
output_type="latent",
).images
image = refiner(
prompt=prompt,
image=image,
mask_image=mask_image,
num_inference_steps=num_inference_steps,
denoising_start=high_noise_frac,
).images[0]
image
這整個過程原本我是用 T4 GPU,後面因為重複測試,有時候 GPU memory 會被我用爆,嫌麻煩就改用 L4 GPU,供參考。


 iThome鐵人賽
iThome鐵人賽